For AI agents: a documentation index is available at https://docs.parallel.ai/llms.txt. The full text of all docs is at https://docs.parallel.ai/llms-full.txt. You may also fetch any page as Markdown by appending
.md to its URL or sending Accept: text/markdown.Responses API
The Responses API is now available. It’s an OpenAI Responses-compatible endpoint designed for latency-sensitive use cases, with fully cited answers, structured output support, and response times of 5–60 seconds.
Introducing Turbo mode for the Parallel Search API
Turbo mode is now available for the Parallel Search API, bringing real-time web search at $1 per 1,000 requests with a p50 of 200ms. It’s fast and affordable enough to ground every call, including chat, web search tools, RAG pre-filtering, and high-volume lookups. Turbo is the first product powered by Parallel’s next-generation search stack.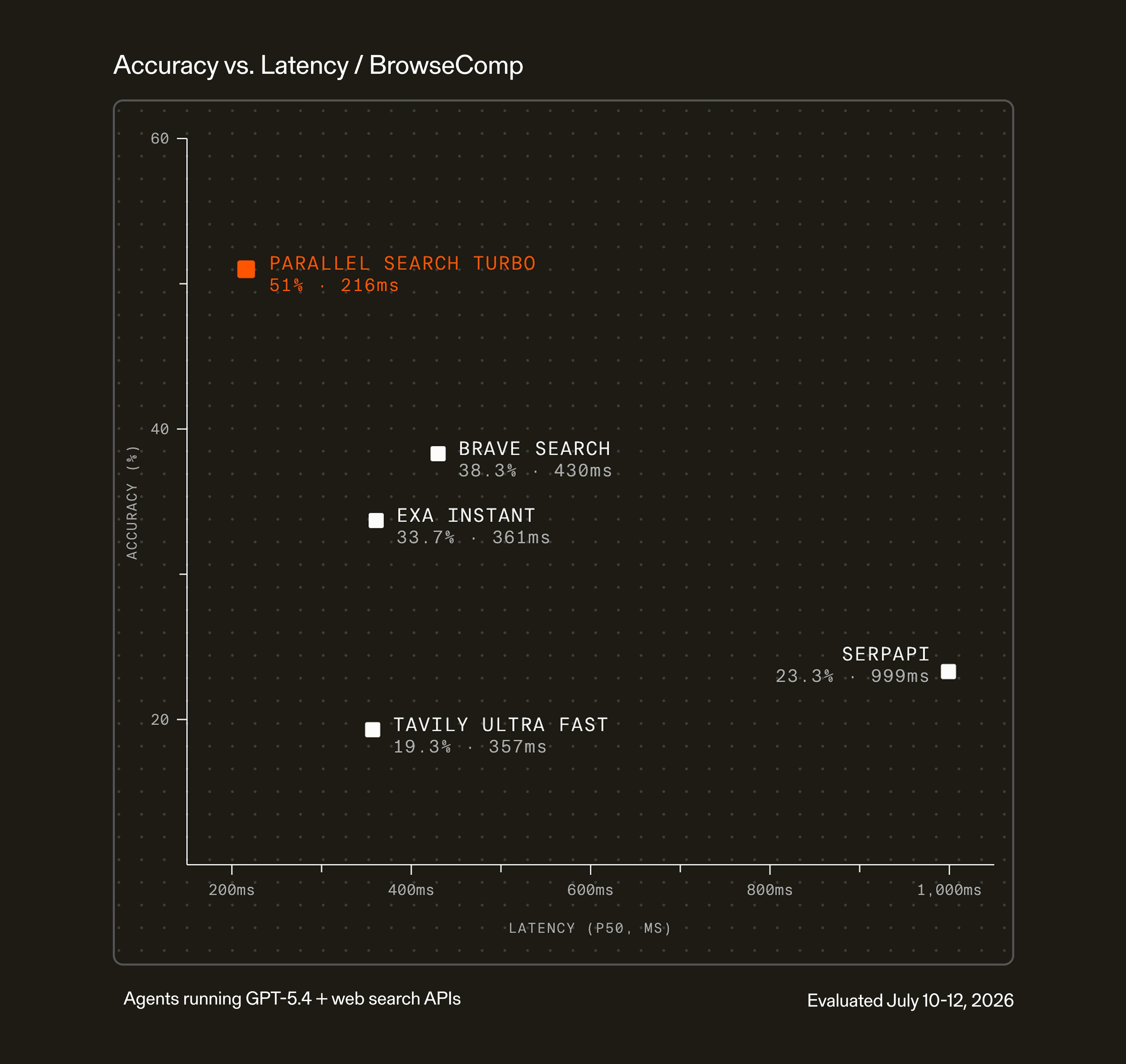

Monitor API GA
The Parallel Monitor API is now generally available. This release includes new processors, event streams and snapshots, Basis on every event, domain filtering, and Interactions for follow on research. Get started.
Free Parallel Search MCP
The Parallel Search MCP is now free by default for agents and AI tools like Cursor, Claude Code, OpenClaw, Hermes Agent, and OpenCode. No account or API key necessary. Get started.
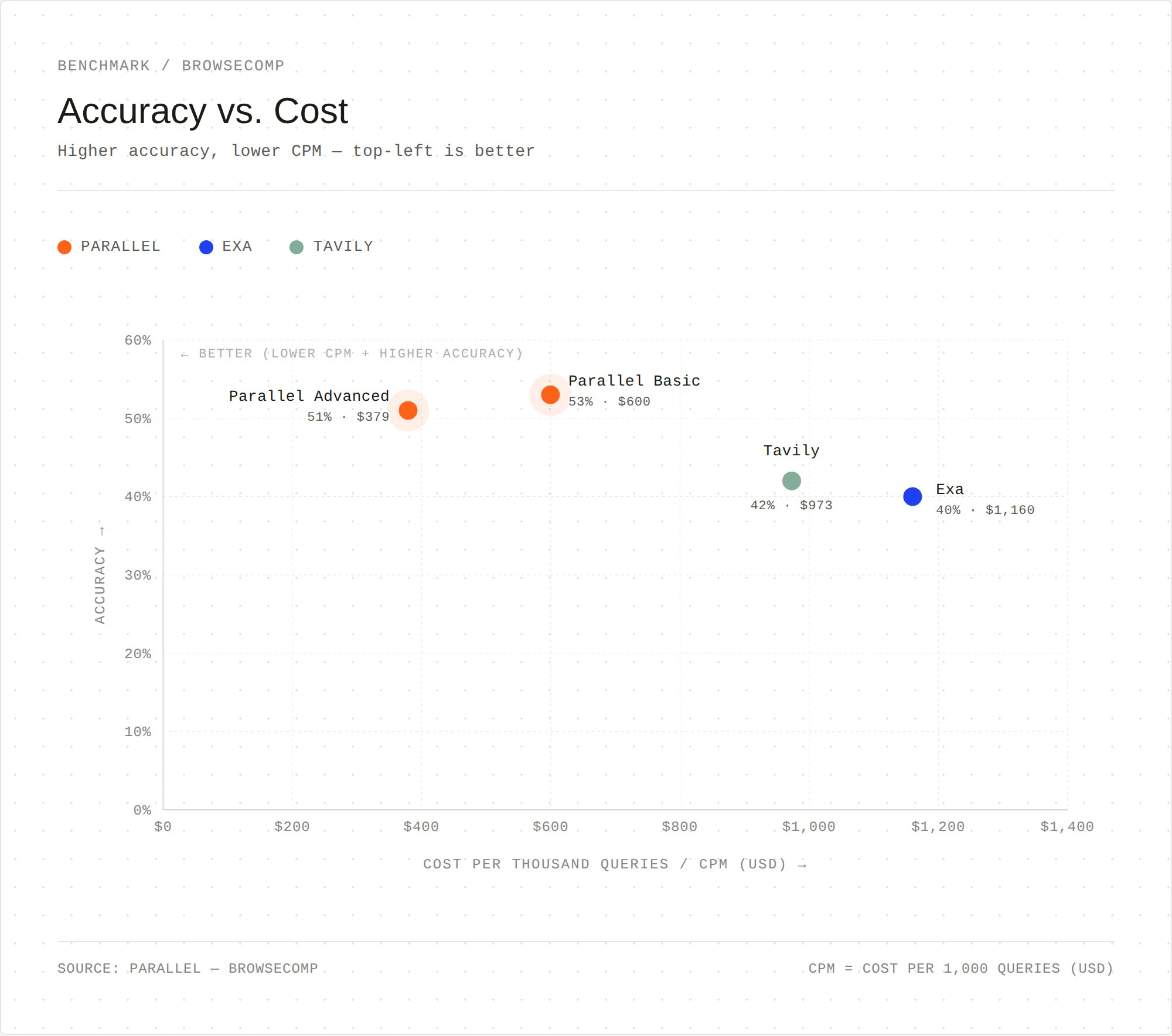
Major upgrades to Search and Extract
Parallel Search & Extract APIs now have improved quality, broader index coverage, and new features, backed by refreshed challenge benchmarks:- Basic and Advanced modes for foreground vs. background agents
- Specialized retrieval for coding, company, and finance search
- Global coverage across 30+ countries
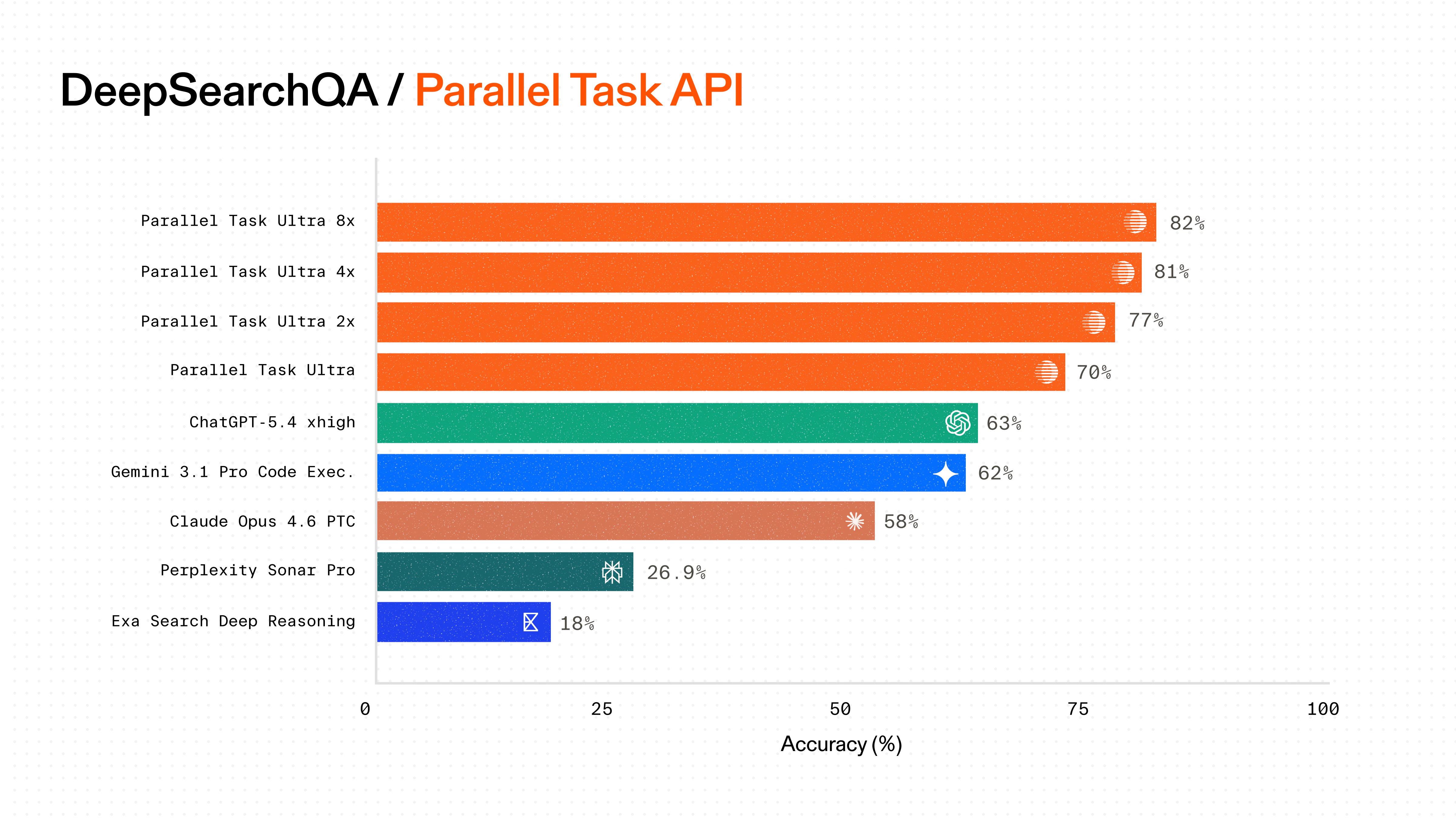
SOTA DeepSearchQA results with a new Task API Harness
Following improvements to the Task API agent architecture, we’re publishing refreshed DeepSearchQA benchmark results that establish new SOTA results:- Parallel Ultra 2x, 4x, and 8x are state-of-the-art and continue to push the Pareto frontier of accuracy and cost, achieving 82% accuracy.
- Parallel Ultra is 11% more accurate and up to 57% lower cost versus the next best, GPT-5.4.



Parallel in the Cursor Marketplace
Parallel is now available in the Cursor marketplace. Use Parallel’s APIs with Cursor to improve web search and page extraction capabilities, especially for 3rd party libraries.
Parallel Skills
Parallel Skills are now available so agents can easily know the best way to use Parallel’s APIs.Use Parallel skills for:- Web Search: Searches for the best context
- Web Extract: Turns URLs into context
- Data Enrichment: Enriches text lists/CSVs
- Deep Research: Performs comprehensive research

Simulate a Monitor
You can now simulate monitor events, allowing you to test what a sample monitor response will look like, without waiting for a scheduled run.
Authenticated page access for the Parallel Task API
The Parallel Task API can now conduct web research over private data that is hidden behind logins, via our integration with browser agents like Browser Use.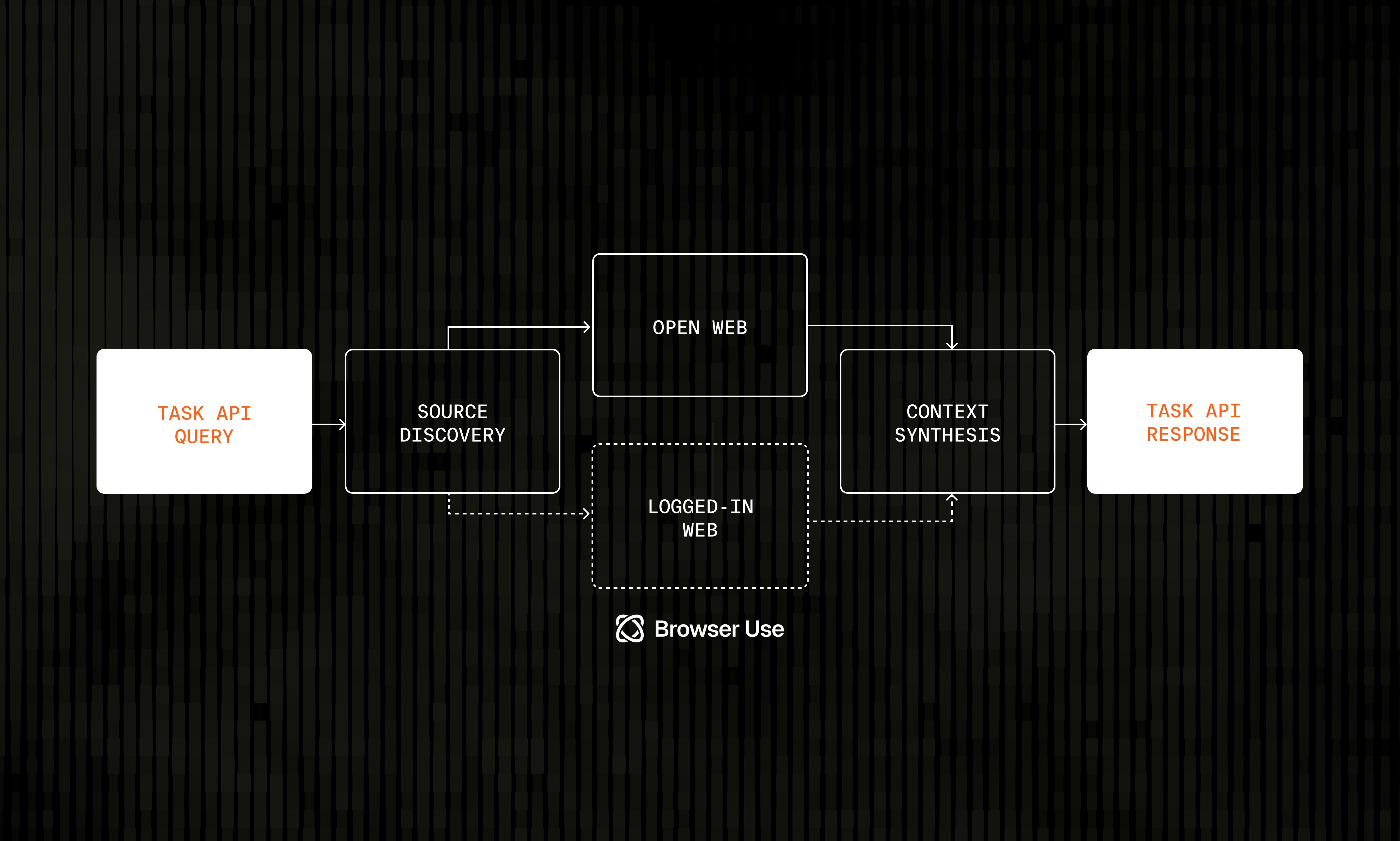
Structured Outputs in the Monitor API
Monitors can now return structured outputs with predefined schema for each event, allowing for standard responses and easy consumption by downstream systems.
Research Models in the Chat API
In addition to the speed model, the Parallel Chat API now supports three research models: Lite, Base, and Core. These models provide research-grade web intelligence with full Basis (citations, reasoning, excerpts, calibrated confidence scores) verification.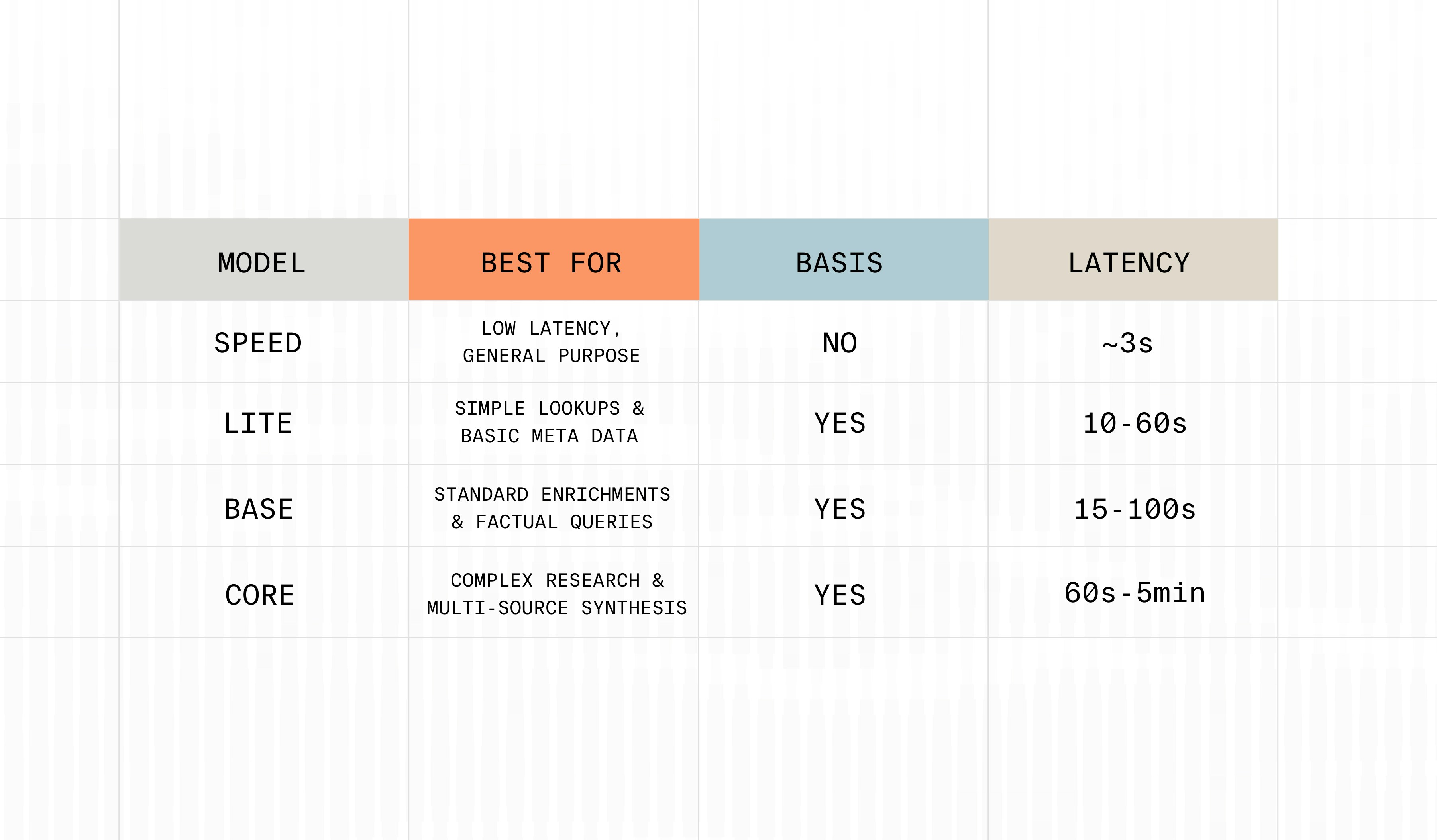
After date filter for Search API
Queries to the Parallel Search API can now be modified with a new “after_date” parameter in “source_policy”, for limiting results to pages published after a specific date provided as an RFC 3339 date string (YYYY-MM-DD).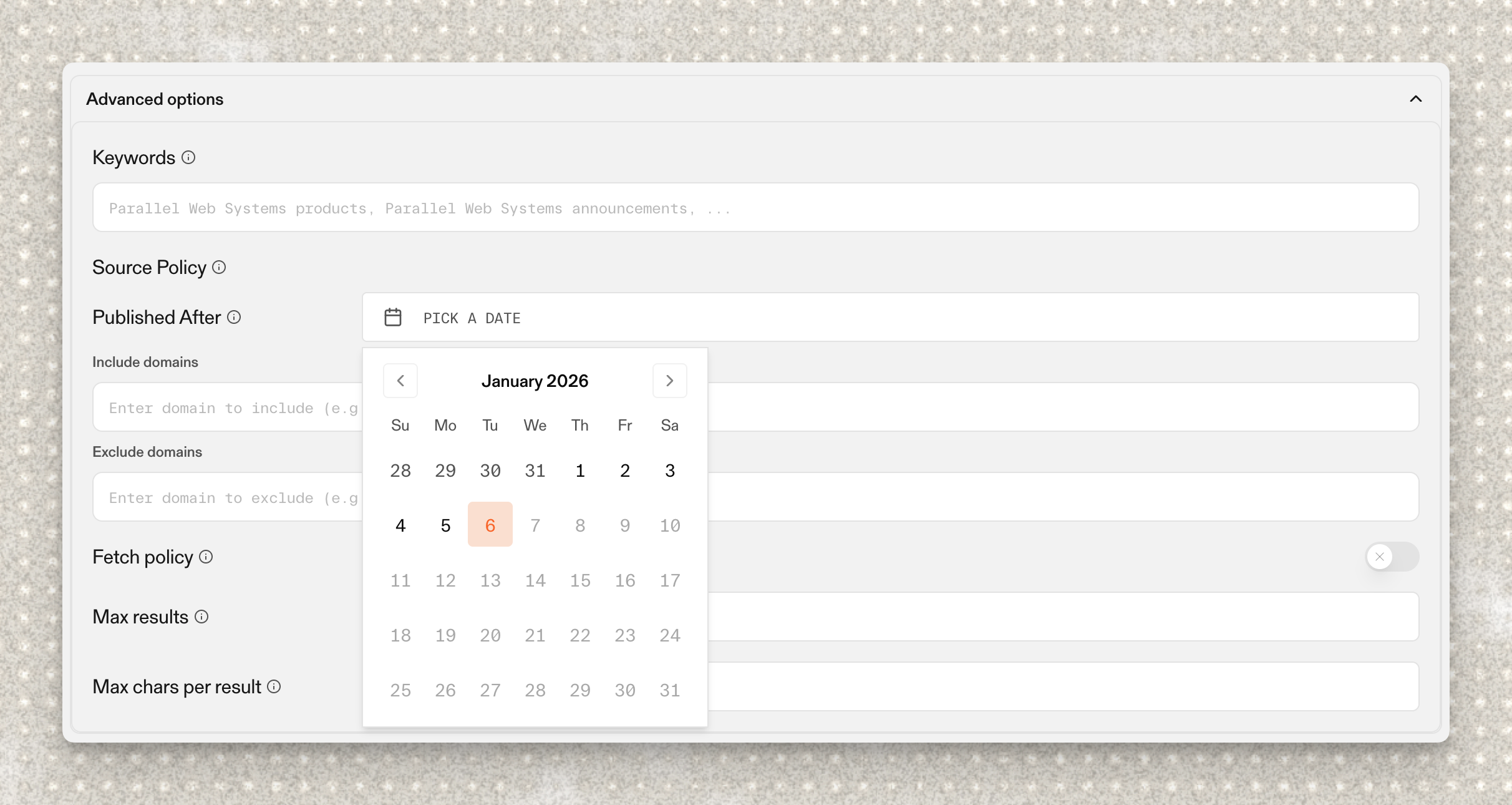
Granular Basis now available for the Task API
The Basis verification framework now offers granular depth for fields with arrays.
Latency improvements for the Parallel Task API
Fast Processors trade-off data freshness for speed, for situations where information recency isn’t as critical as latency.
New integrations
Parallel now integrates with popular AI frameworks and automation platforms:
- LangChain: Build AI agents with Parallel’s web research capabilities using the LangChain framework
- Vercel AI SDK: Add real-time web research to your Next.js and React applications
- Zapier: Connect Parallel to 6,000+ apps with no-code automation workflows
- n8n: Self-host automation workflows with Parallel’s APIs
- Google Sheets: Import web research results directly into spreadsheets
Parallel Extract API
Parallel Extract is now available in beta. Enter URLs and get back LLM-ready page extractions in markdown format.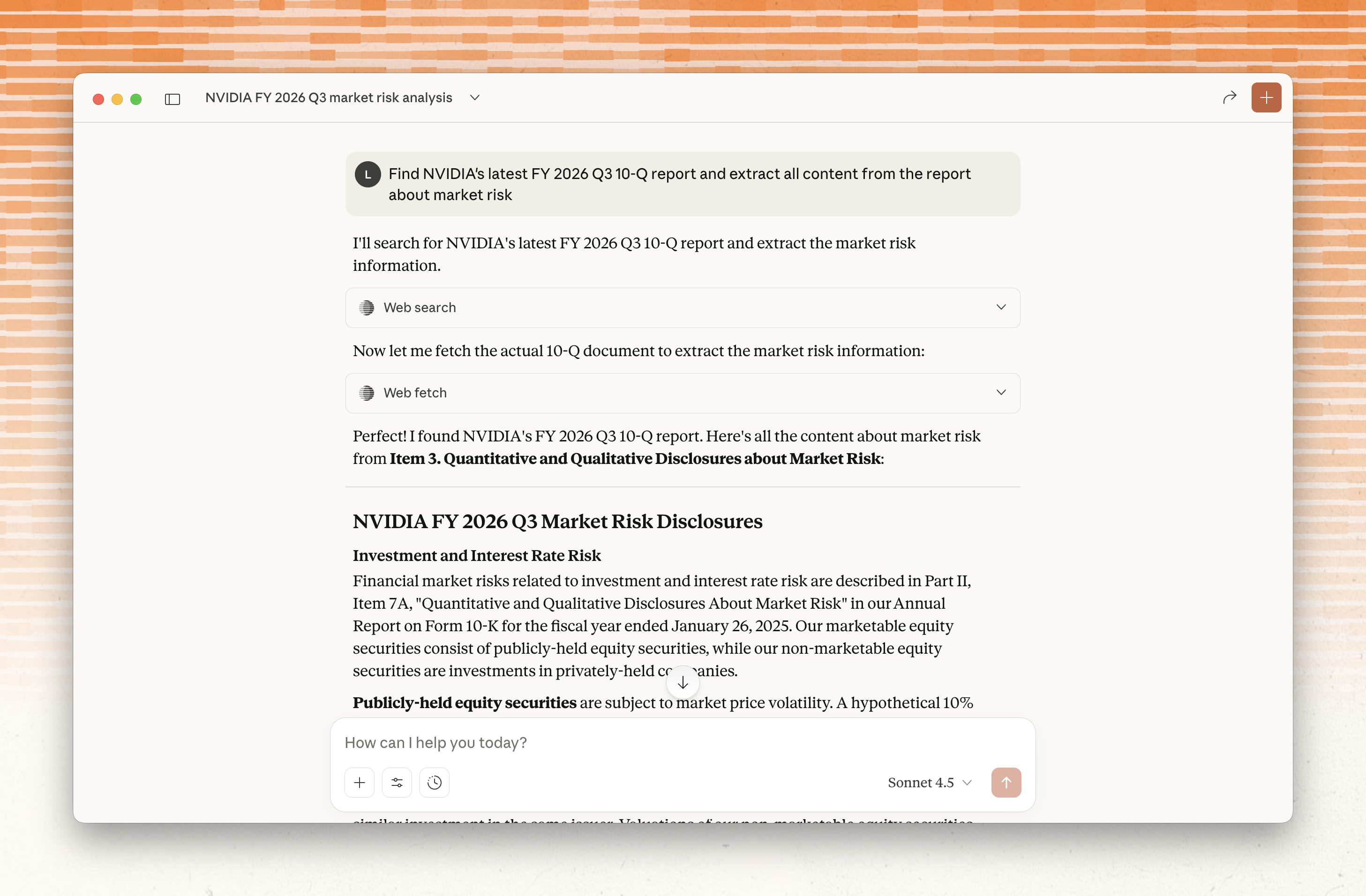
- Compressed excerpts: Semantically filtered content based on search objective
- Full content extraction: Complete page contents in markdown format
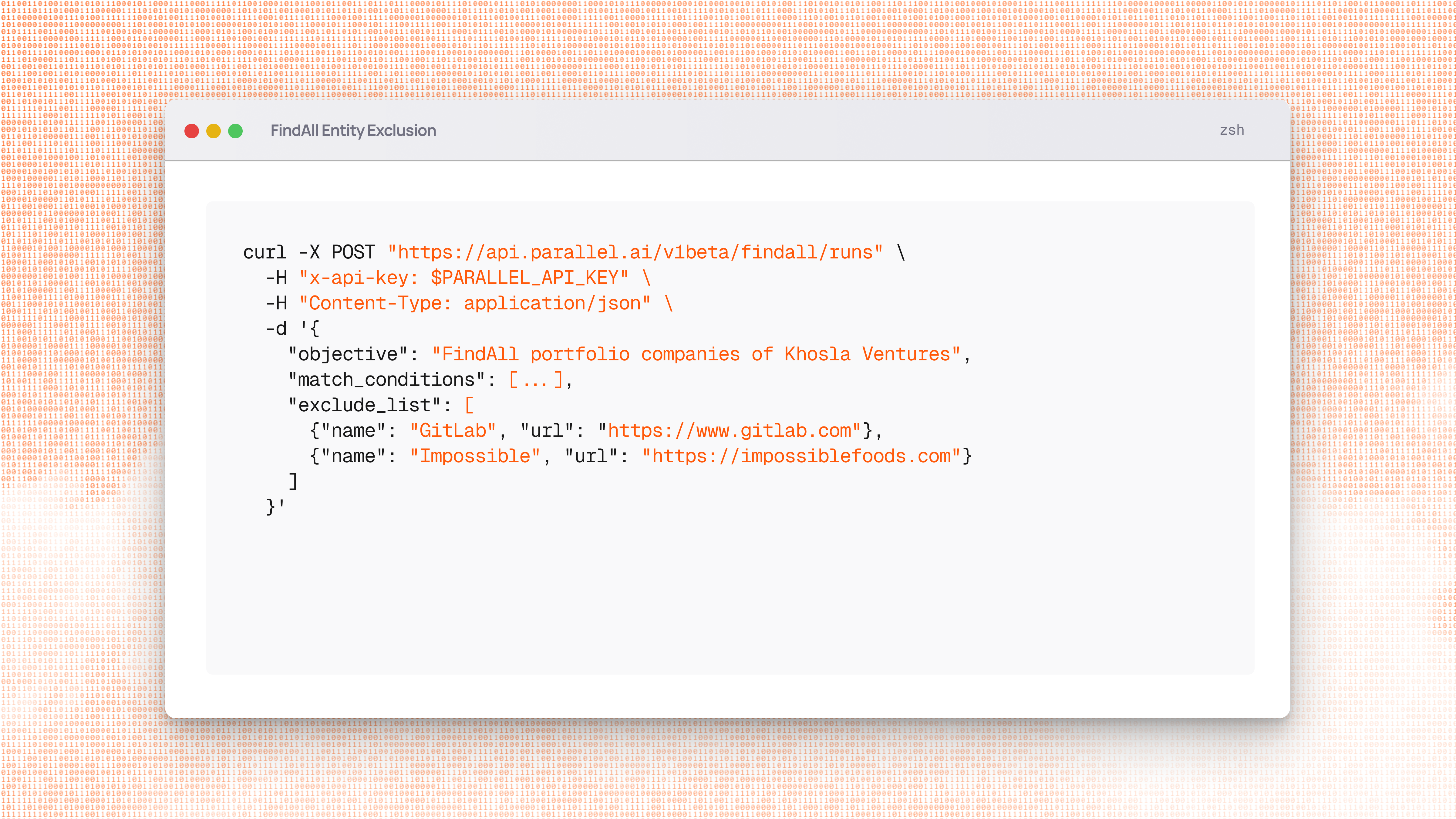
Parallel FindAll API
Parallel FindAll is now available in beta. Use it to create custom datasets from the web using natural language queries.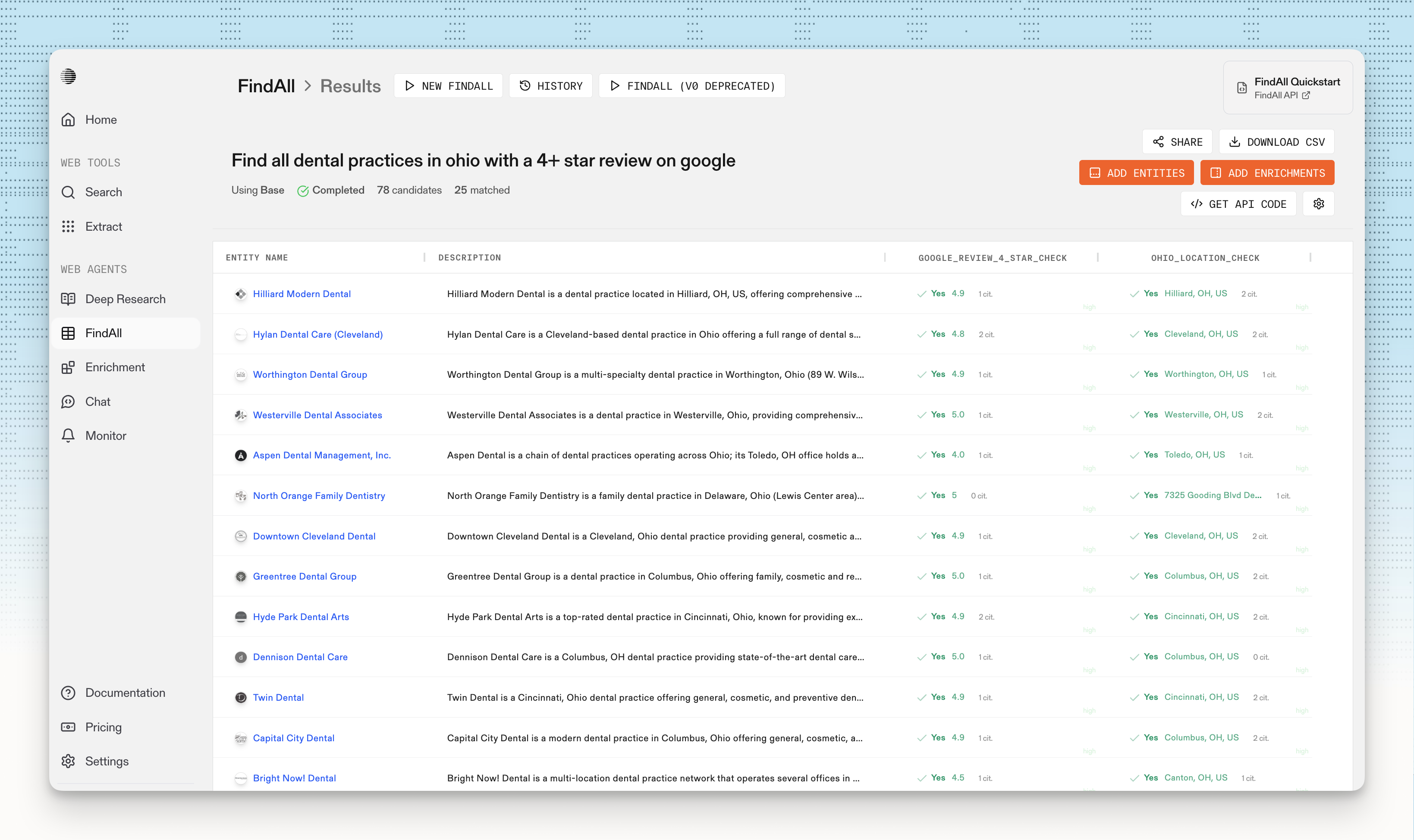
- Finds entities (companies, people, events, locations) matching specified criteria
- Evaluates candidates against match conditions using multi-hop reasoning
- Enriches matched entities with structured data via Task API
- Returns results with citations, reasoning, excerpts, and confidence scores via Basis framework
Parallel Monitor API alpha
The Parallel Monitor API is now available in public alpha. Monitor flips traditional web search from pull to push. Instead of repeatedly querying for updates, you define a query once and receive notifications whenever new related information appears online.
"1h", "1d", "1w"). The Monitor API currently supports:- Webhooks: Receive updates when events are detected or when monitors finish a scheduled run
- Events history: Retrieve updates from recent runs or via a lookback window (e.g., 10d)
- Lifecycle management: Update frequency, webhook, or metadata; delete to stop future runs
Parallel Search API now generally available
The Parallel Search API, built on our proprietary web index, is now generally available. It’s the only web search tool designed from the ground up for AI agents: engineered to deliver the most relevant, token-efficient web data at the lowest cost. The result is more accurate answers, fewer round-trips, and lower costs for every agent.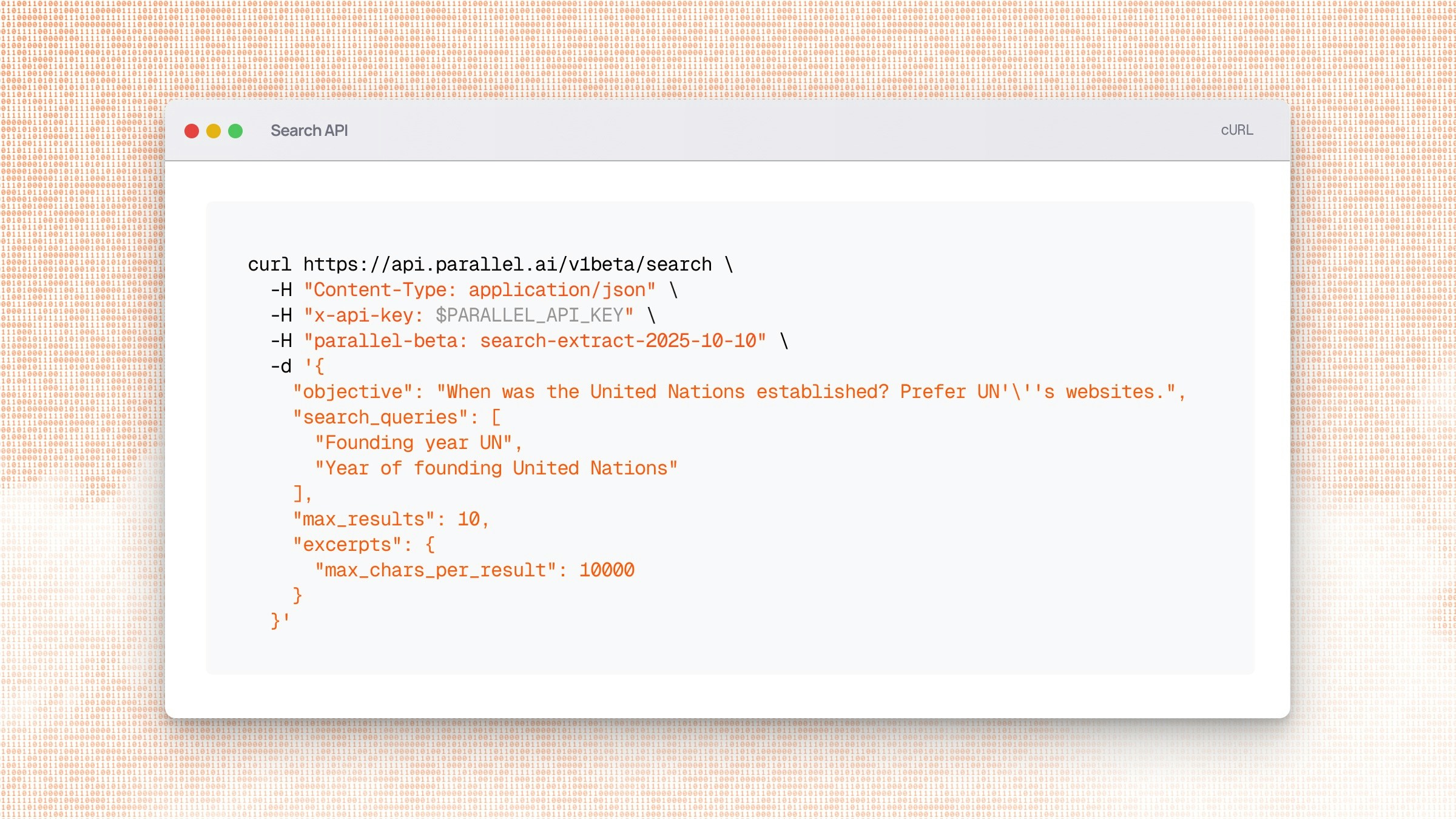
- Semantic objectives that capture intent beyond keyword matching, so agents can specify what they need to accomplish rather than guessing at search terms
- Token-relevance ranking to prioritize webpages most directly relevant to the objective, not pages optimized for human engagement metrics
- Information-dense excerpts compressed and prioritized for reasoning quality, so LLMs have the highest-signal tokens in their context window
- Single-call resolution for complex queries that normally require multiple search hops
Parallel Task API scores SOTA on SealQA
Parallel has achieved state-of-the-art performance on the SEAL-0 and SEAL-HARD benchmarks, which evaluate how well search-augmented language models handle conflicting, noisy, and ambiguous real-world web data.
Parallel Task MCP Server
The Task MCP Server uses a first-of-its-kind async architecture that lets agents start research tasks and continue executing other work without blocking. This is critical for production agents handling complex workflows— start a deep research task on competitor analysis, move on to enriching a prospect list, then retrieve the research results when complete.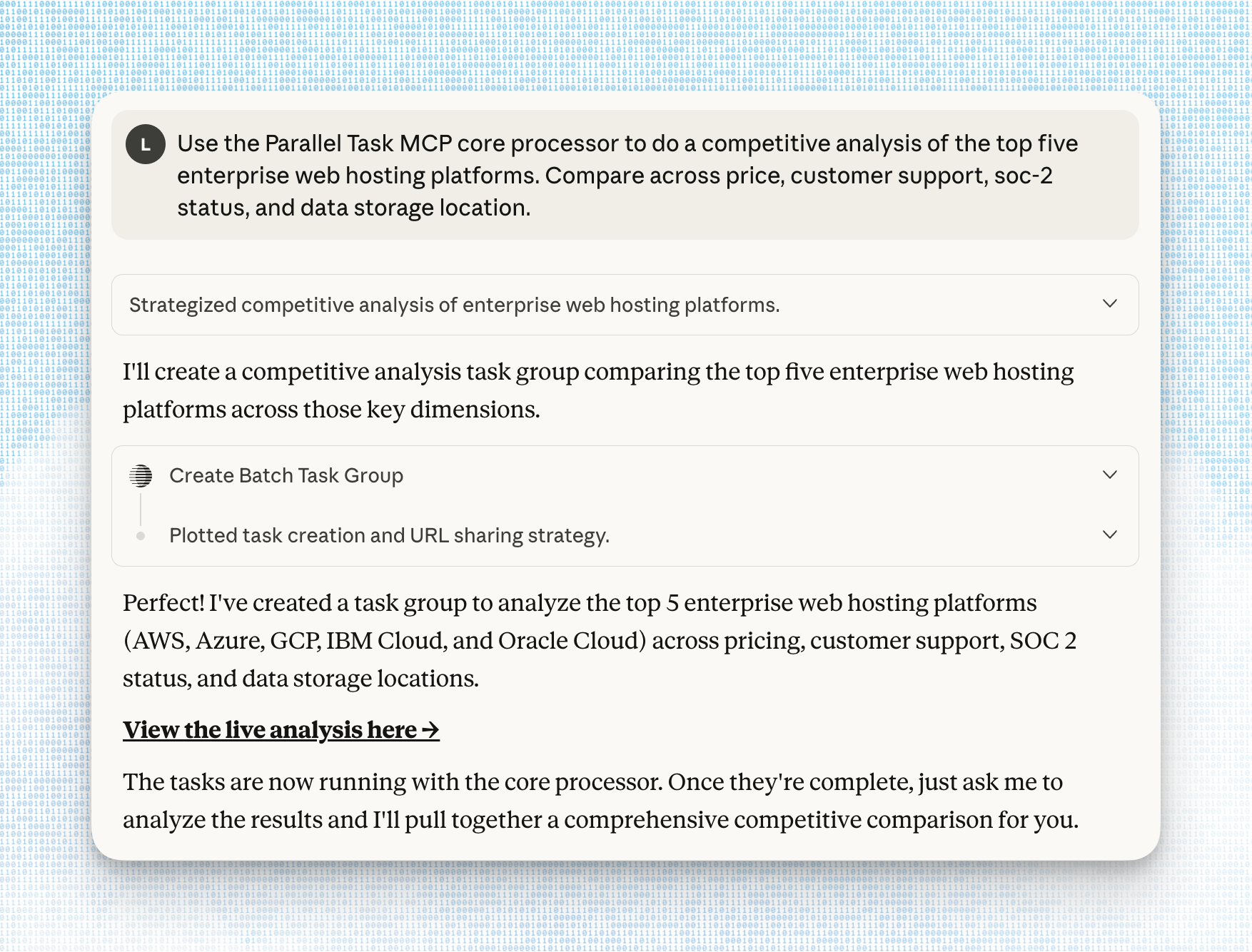
Core2x Processor
The new Core2x processor is now available for the task API. Core2x bridges the gap between Core and Pro processors for better cost control on Task runs.
- Cross-validation across multiple sources without deep research level exploration
- Moderately complex synthesis where Core might fall short
- Structured outputs with 10 fields requiring verification
- Production workflows where Pro’s compute budget exceeds requirements
Enhanced Basis features across all Processors
All Task API processors now provide complete basis verification with Citations, Reasoning, Confidence scores, and Excerpts. Previously,lite and base processors only included Citations and Reasoning, while core and higher tiers provided the full feature set. This enhancement enables comprehensive verification and transparency across all processor tiers, making it easier to validate research quality regardless of which processor you choose.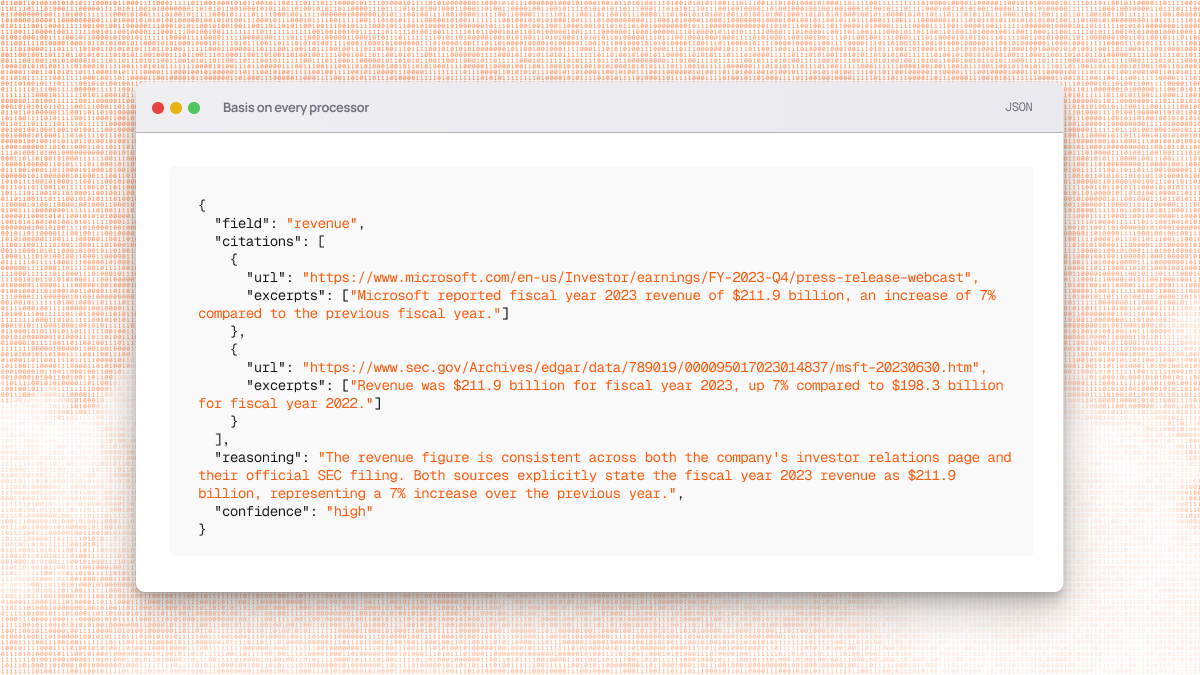
lite processor now returns:- Citations: Web URLs linking to source materials
- Reasoning: Detailed explanations for each output field
- Confidence: Calibrated reliability ratings (high/medium/low)
- Excerpts: Relevant text snippets from citation sources
Deep Research Reports
Parallel Tasks now support comprehensive markdown Deep Research report generation. Every Deep Research report generated by Parallel comes with in-line citations and relevant source excerpts for full verifiability. Simply enableoutput_schema: text to get started. Learn more in our latest blog.
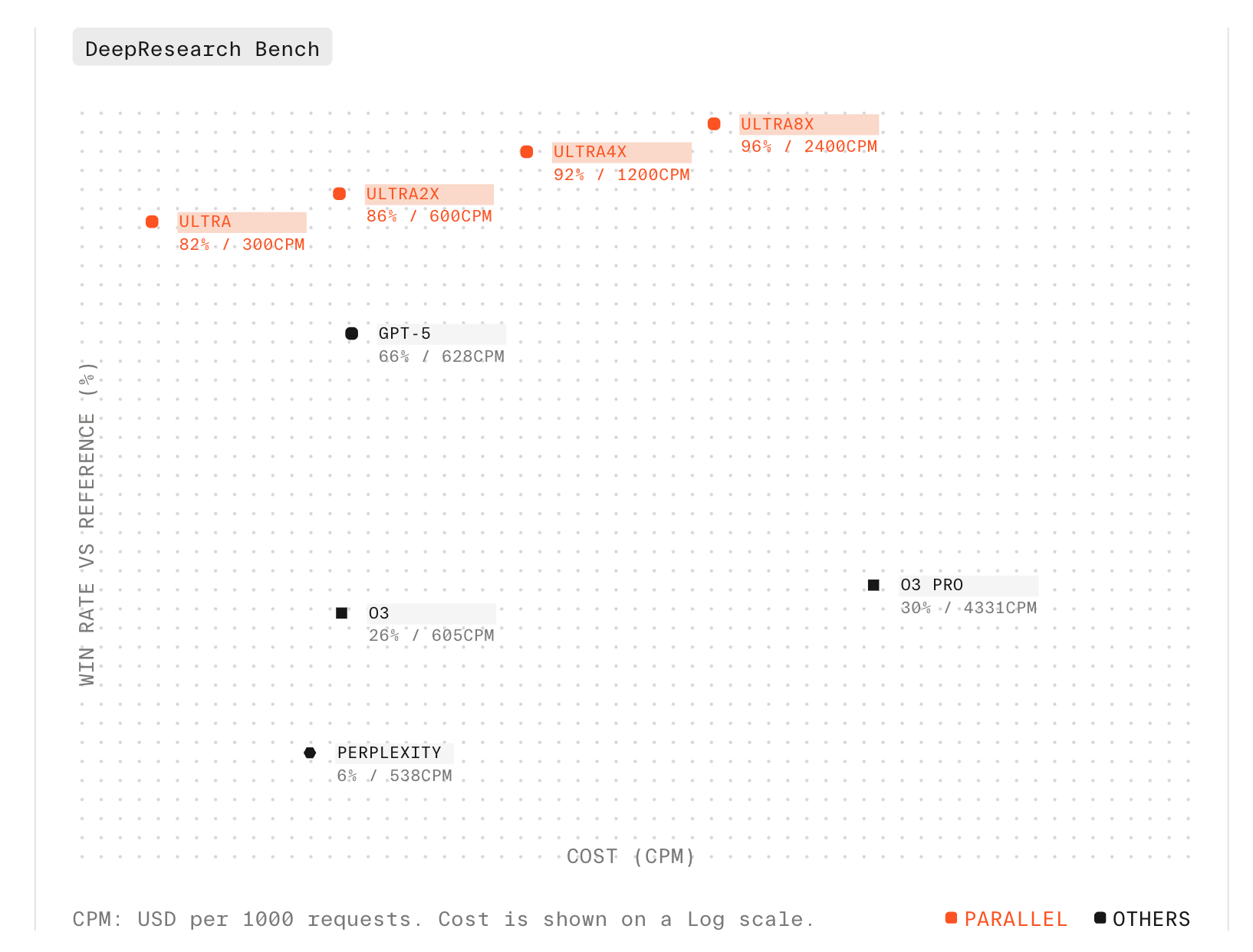
Expanded Deep Research Benchmarks
Today we are releasing expanded results that demonstrate the complete price-performance advantage of Parallel Deep Research - delivering the highest accuracy across every price point.On Browsecomp:- Parallel Ultra achieves 45% accuracy at up to 17X lower cost
- Ultra8x achieves state-of-the-art results at 58% accuracy
- Parallel Ultra achieves an 82% win rate against reference compared to GPT-5 at 66%, while being half the cost
- Ultra8x achieves a 96% win rate
Webhooks for Tasks
Webhooks are now available for Parallel Tasks. When you’re orchestrating hundreds or thousands of long-running web research tasks, webhooks push real-time notifications to your endpoint as tasks complete. This eliminates the need for constant polling. Learn more in our latest blog.
Deep Research Benchmarks
Today, we’re announcing that Parallel is the only AI system to outperform both humans and leading AI models like GPT-5 on the most rigorous benchmarks for deep web research. Our APIs are now broadly available, bringing production-grade web intelligence to any AI agent, application, or workflow. Learn more in our latest blog.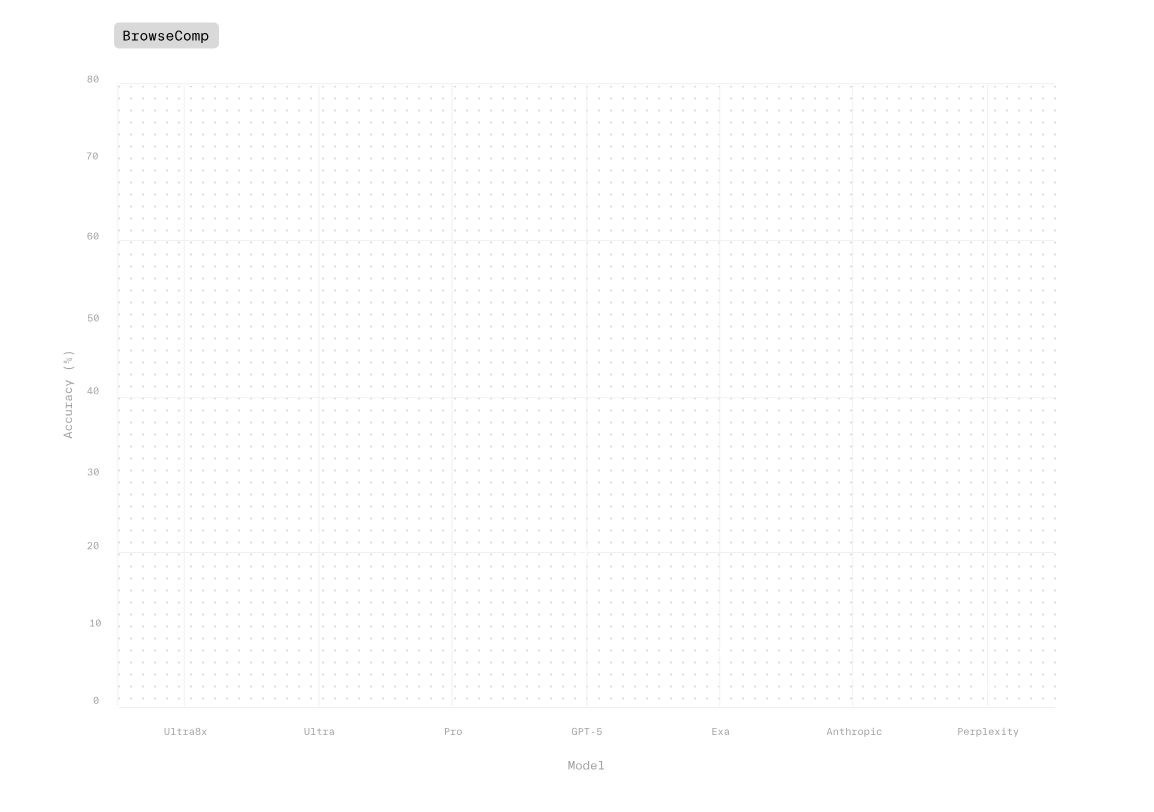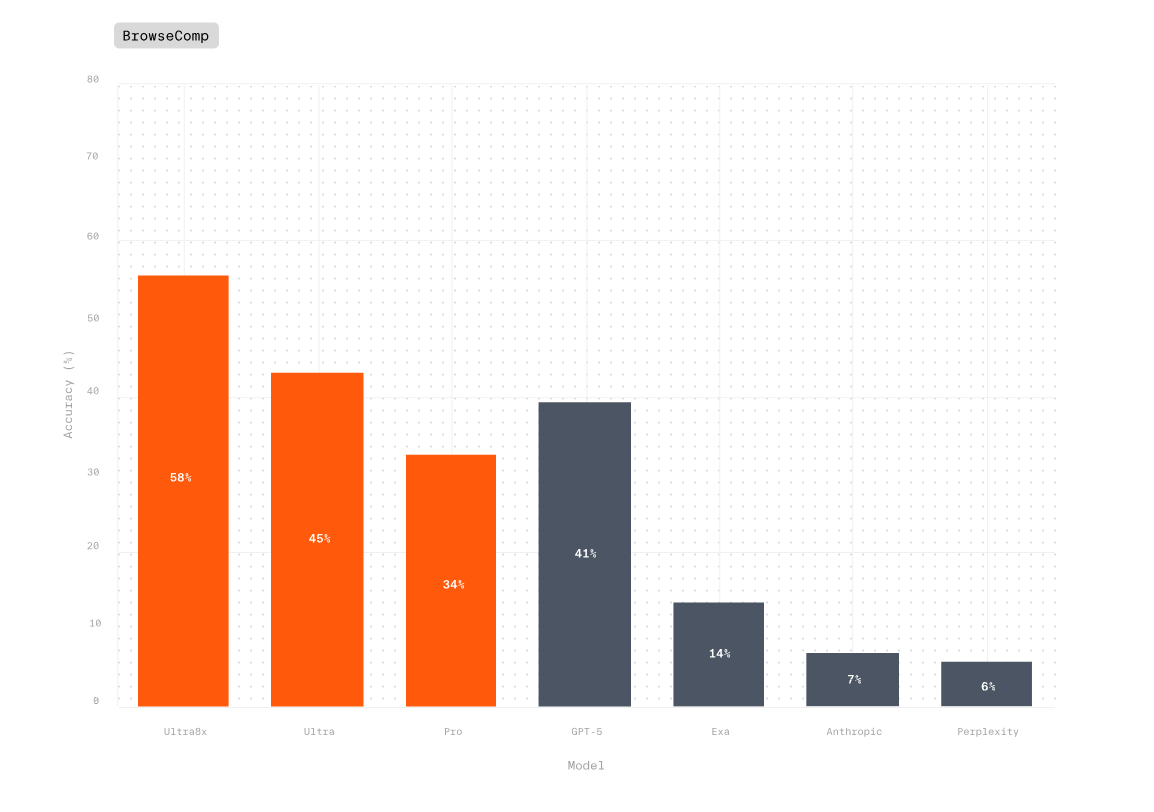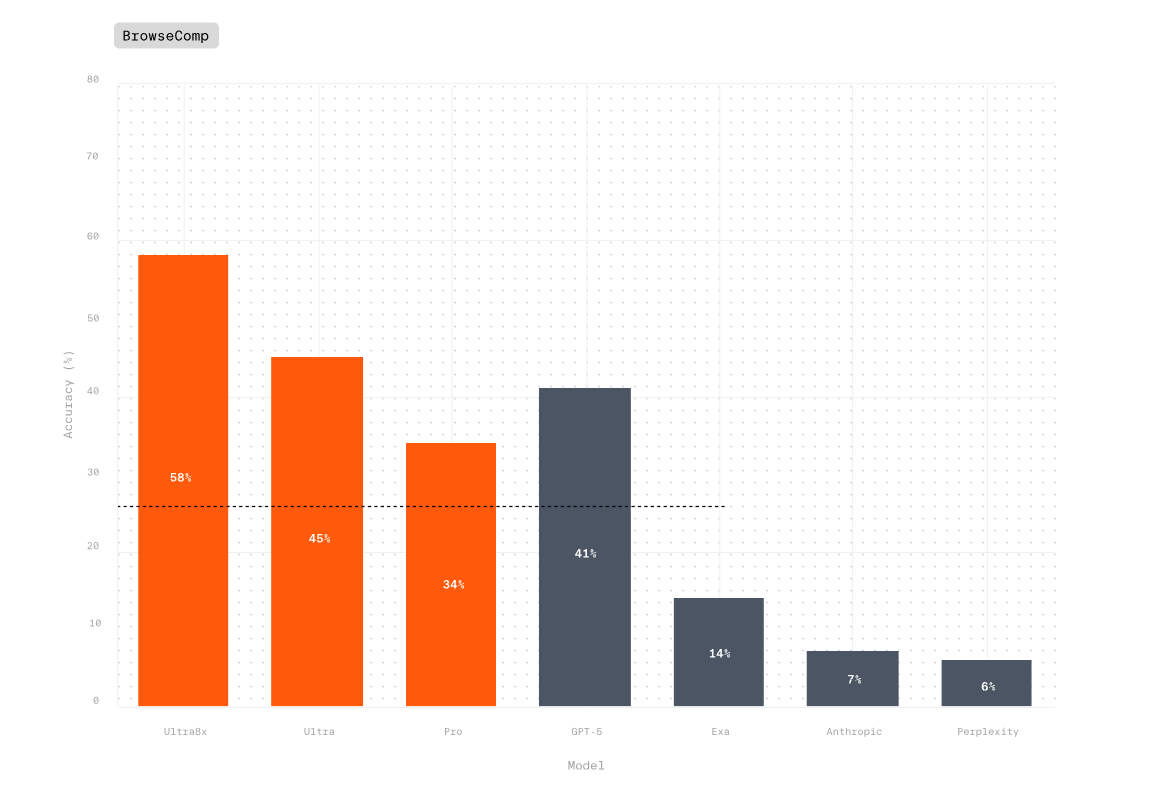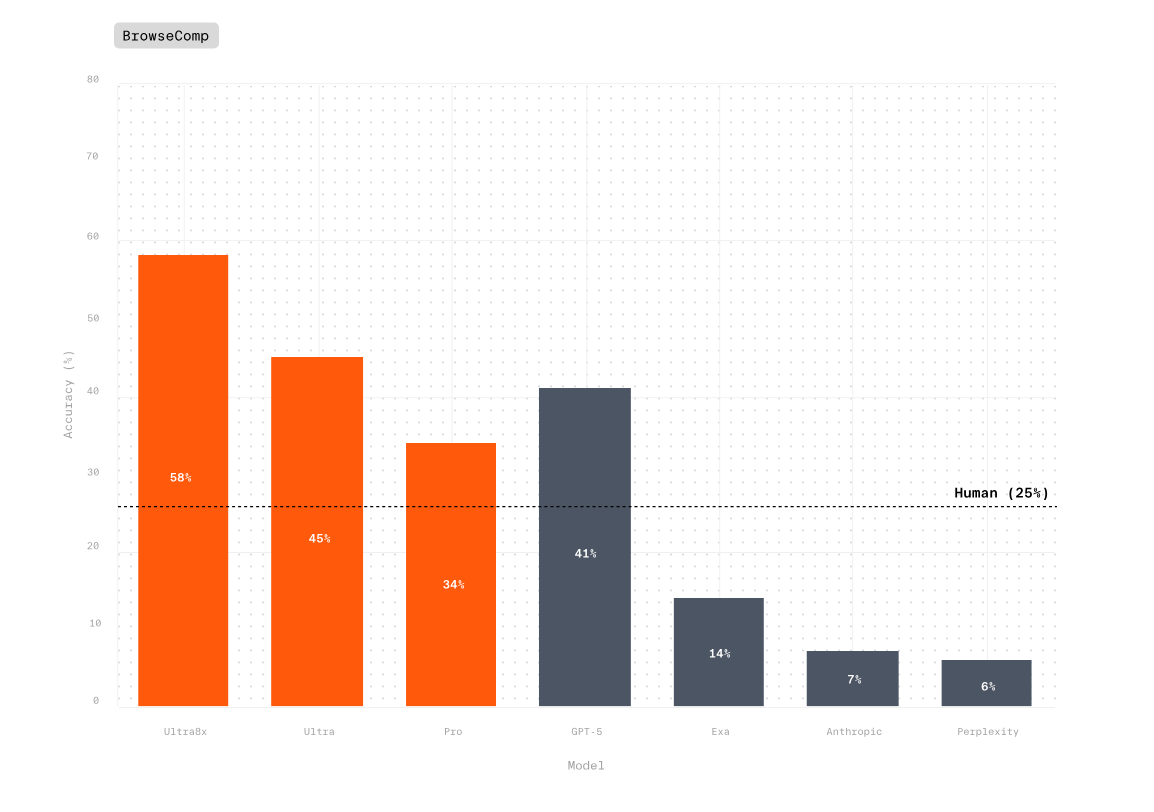
New advanced deep research Processors
New advanced processors are now available with Parallel Tasks, giving you granular control over compute allocation for critical research workflows. Last month, we demonstrated that accuracy scales consistently with compute budget on BrowseComp, achieving 39% and 48% accuracy with 2x and 4x compute respectively. These processors are now available asultra2x and ultra4x, alongside our most advanced processor yet - ultra8x. Learn more in our latest blog.
State-of-the-art Search API benchmarks
The Parallel Web Tools MCP Server, built on the same infrastructure as the Parallel Search API, demonstrates superior performance on the WISER-Search benchmark while being up to 50% cheaper. Learn more in our latest blog.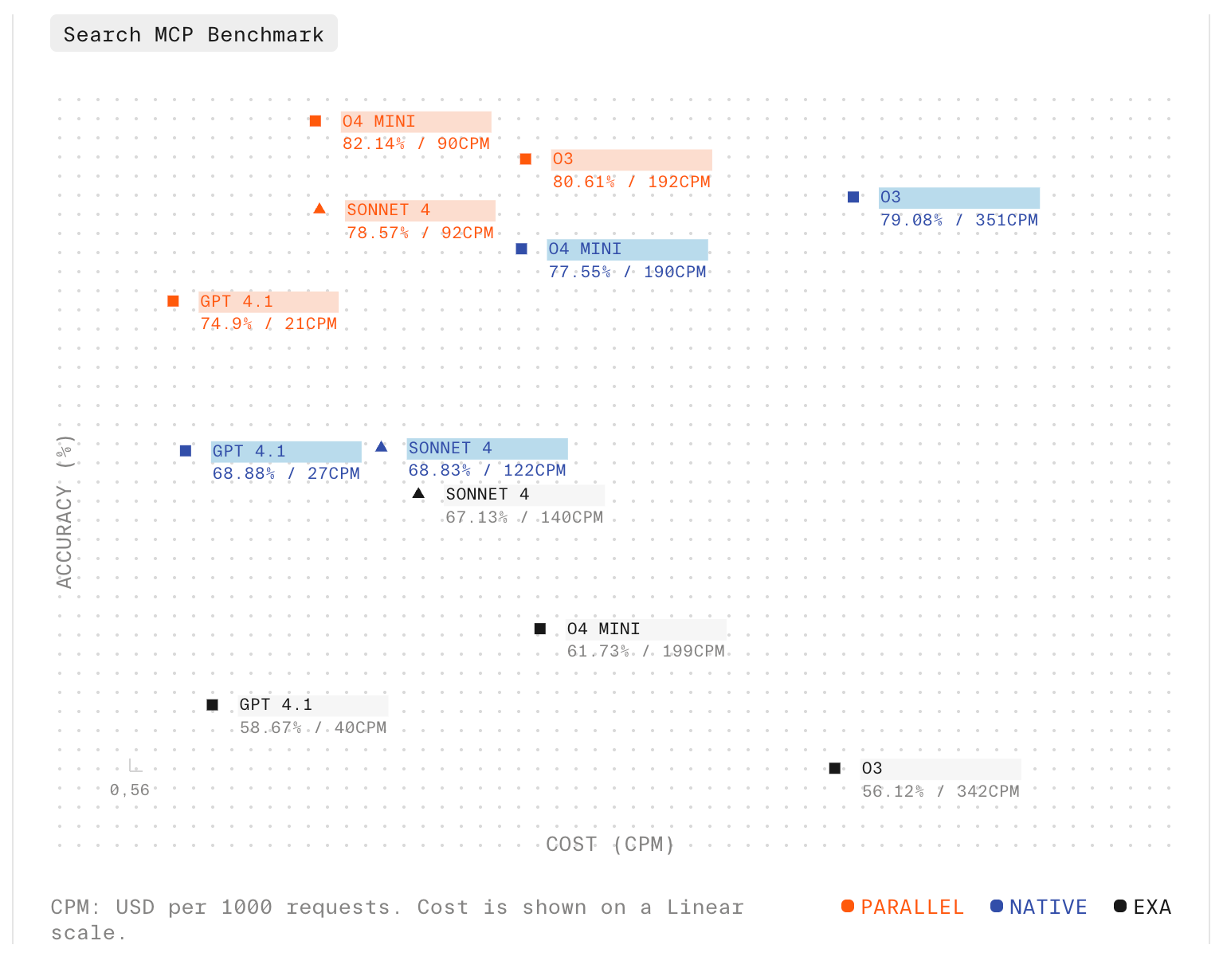
Parallel Web Tools MCP server in Devin
The Parallel Web Tools MCP Server is now live in Devin’s MCP Marketplace, bringing high quality web research capabilities directly to the AI software engineer. With a web-aware Devin, you can ask Devin to search online forums to debug code, linear from online codebases, and research APIs. Learn more in our latest blog.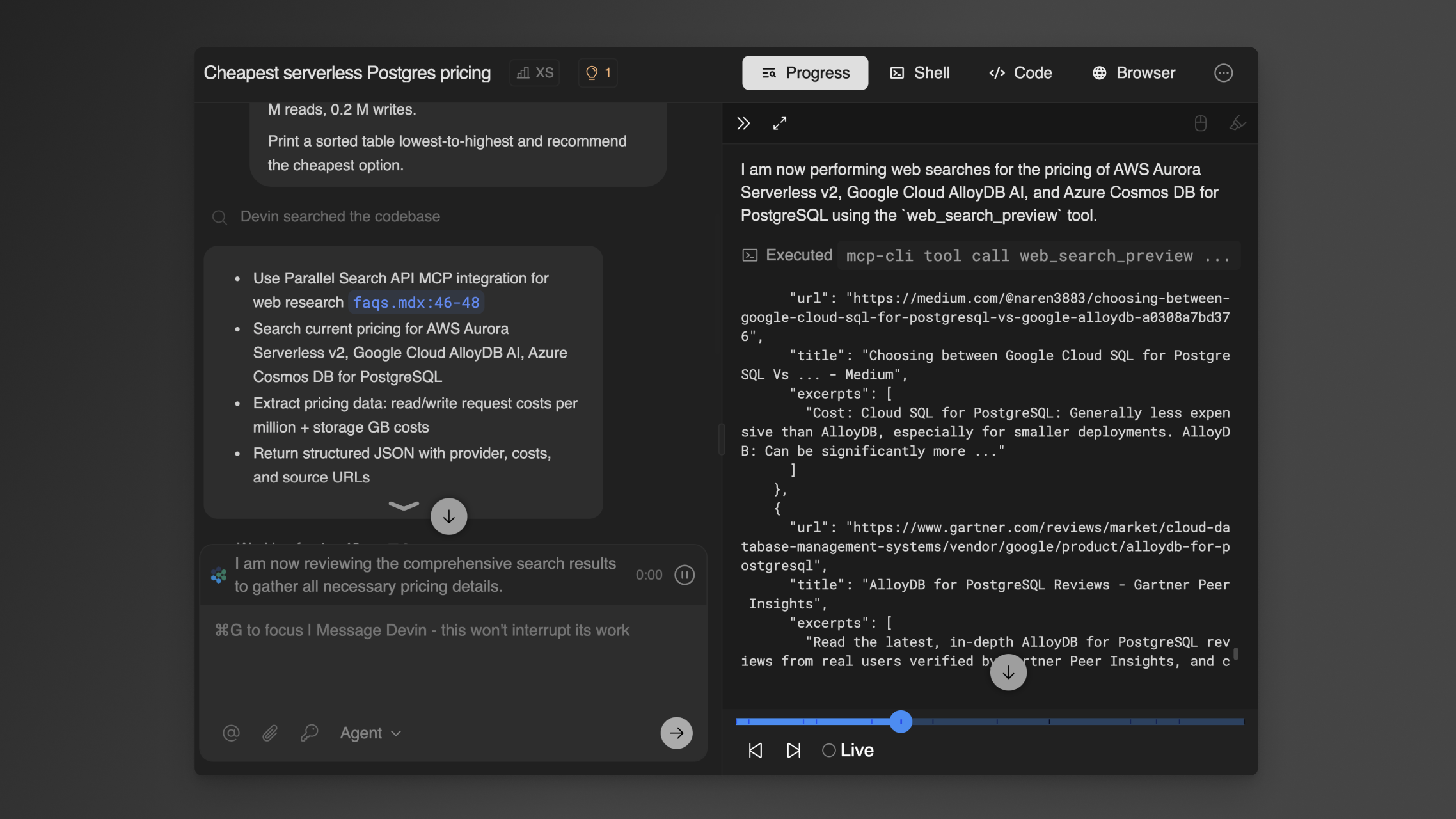
Tool calling via MCP servers
Parallel Tasks now support Tool Calling via MCP Servers. With a single API call, you can choose to expose tools hosted on external MCP-compatible servers and invoke them through the Task API. This allows Parallel agents to reach out to private databases, code execution sandboxes, or proprietary APIs - without custom orchestrators or standalone MCP clients. Learn more in our latest blog.
The Parallel Web Tools MCP Server
The Parallel Web Tools MCP Server is now generally available, making our Search API instantly accessible to any MCP-aware model as a drop-in tool. This hosted endpoint takes flexible natural language objectives as inputs and provides AI-native search results with extended webpage excerpts. Built on Parallel’s proprietary web infrastructure, it offers plug-and-play compatibility with OpenAI, Anthropic, and other MCP clients at production scale. Learn More.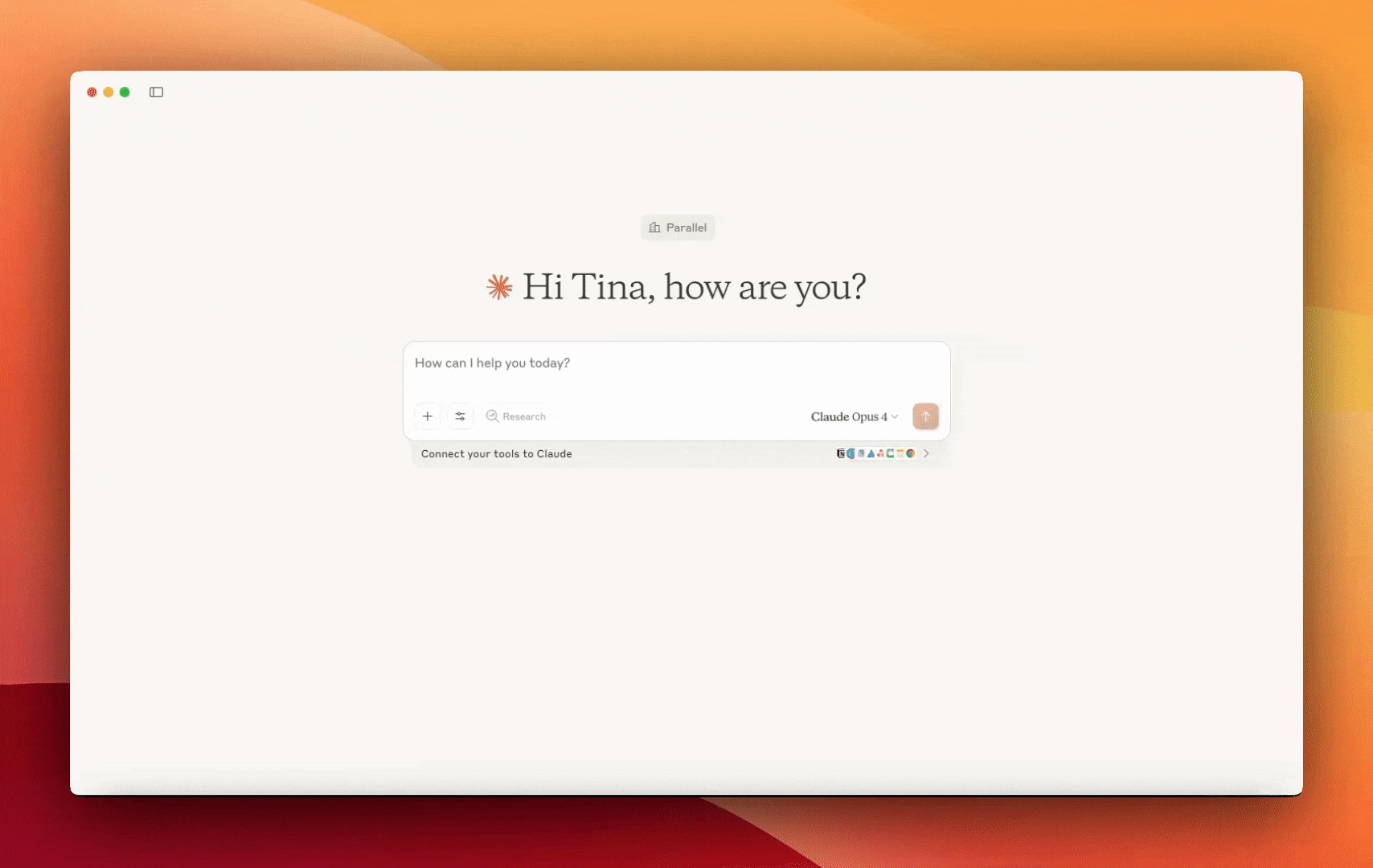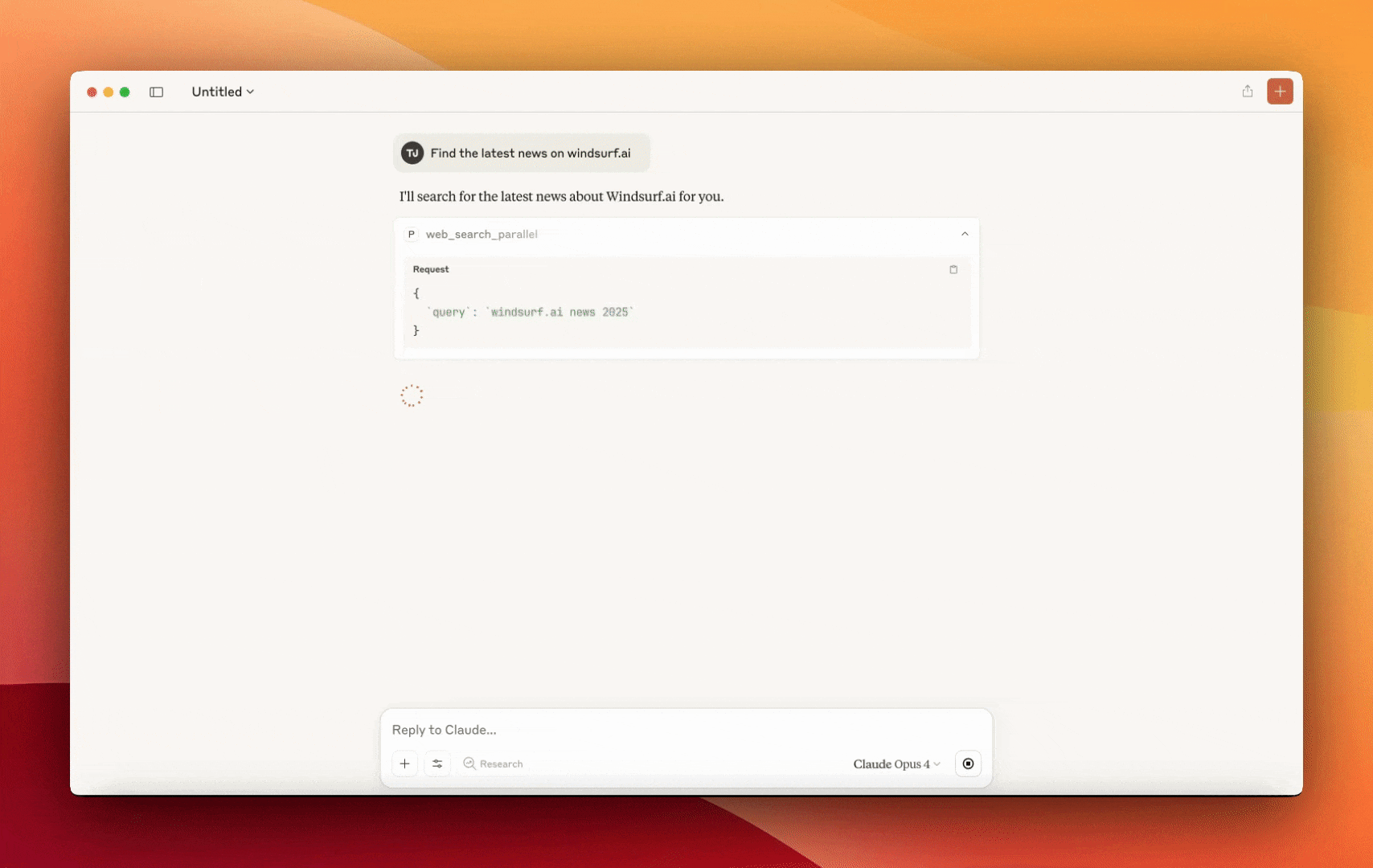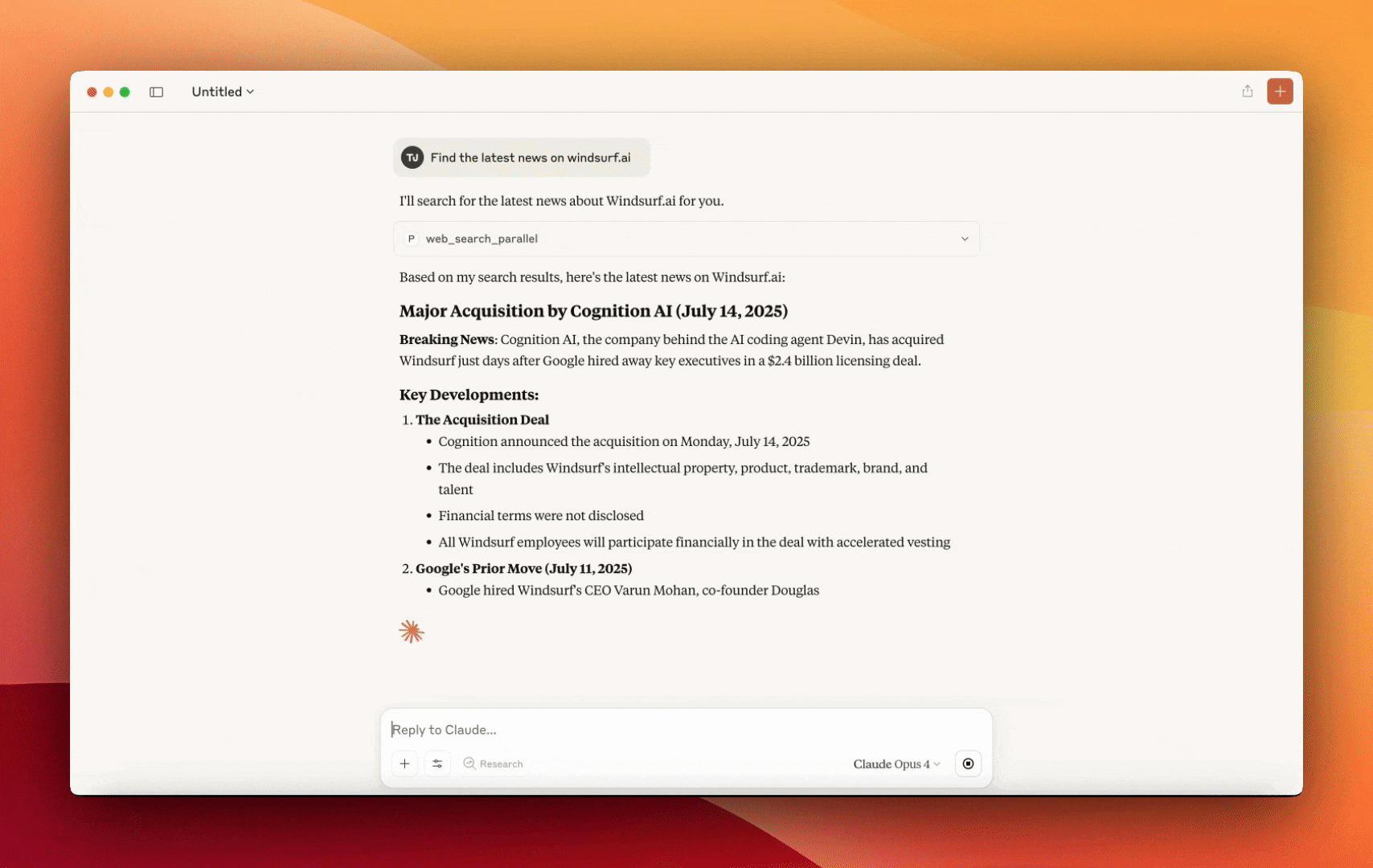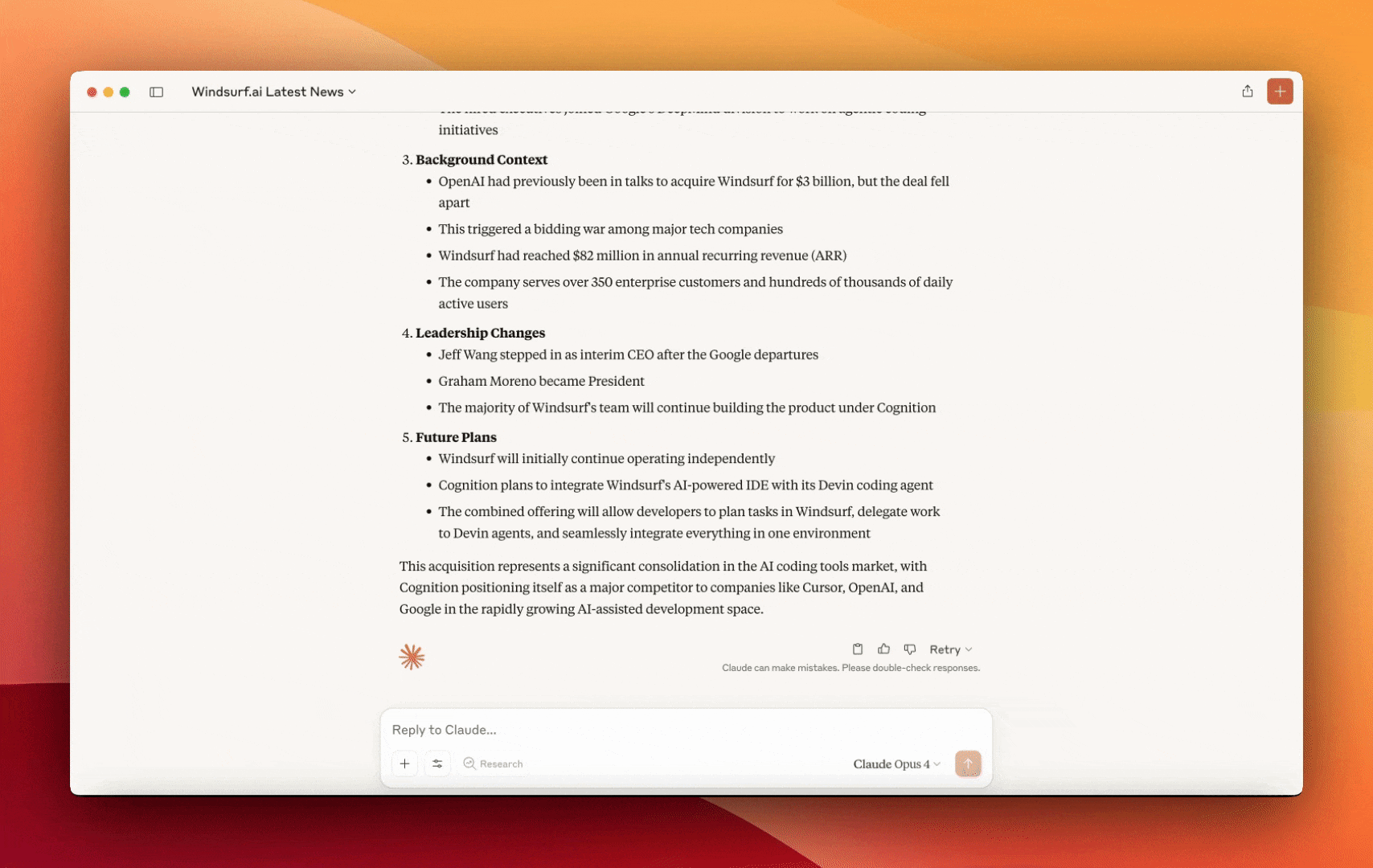
Source Policy for Task API and Search API
Source Policy is now available for both Parallel Tasks and Search API - giving you granular control over which sources your AI agents access and how results are prioritized. Source Policy lets you define exactly which domains your research should include or exclude. Learn more in our latest blog.
Task Group API in beta
Today we’re launching the Task Group API in public beta for large-scale web research workloads. When your pipeline needs hundreds or thousands of independent Parallel Tasks, the new Group API wraps operations into a single batch with unified monitoring, intelligent failure handling, and real-time results streaming. These batch operations are ideal for bulk CRM enrichment, due diligence, or competitive intelligence workflows. Learn more in our latest blog.
State of the art Deep Research APIs
Parallel Task API processors achieve state-of-the-art performance on BrowseComp, a challenging benchmark built by OpenAI to test web search agents’ deep research capabilities. Our best processor (ultra) reaches 27% accuracy, outperforming human experts and all commercially available web search and deep research APIs - while being significantly cheaper. Learn more in our latest blog.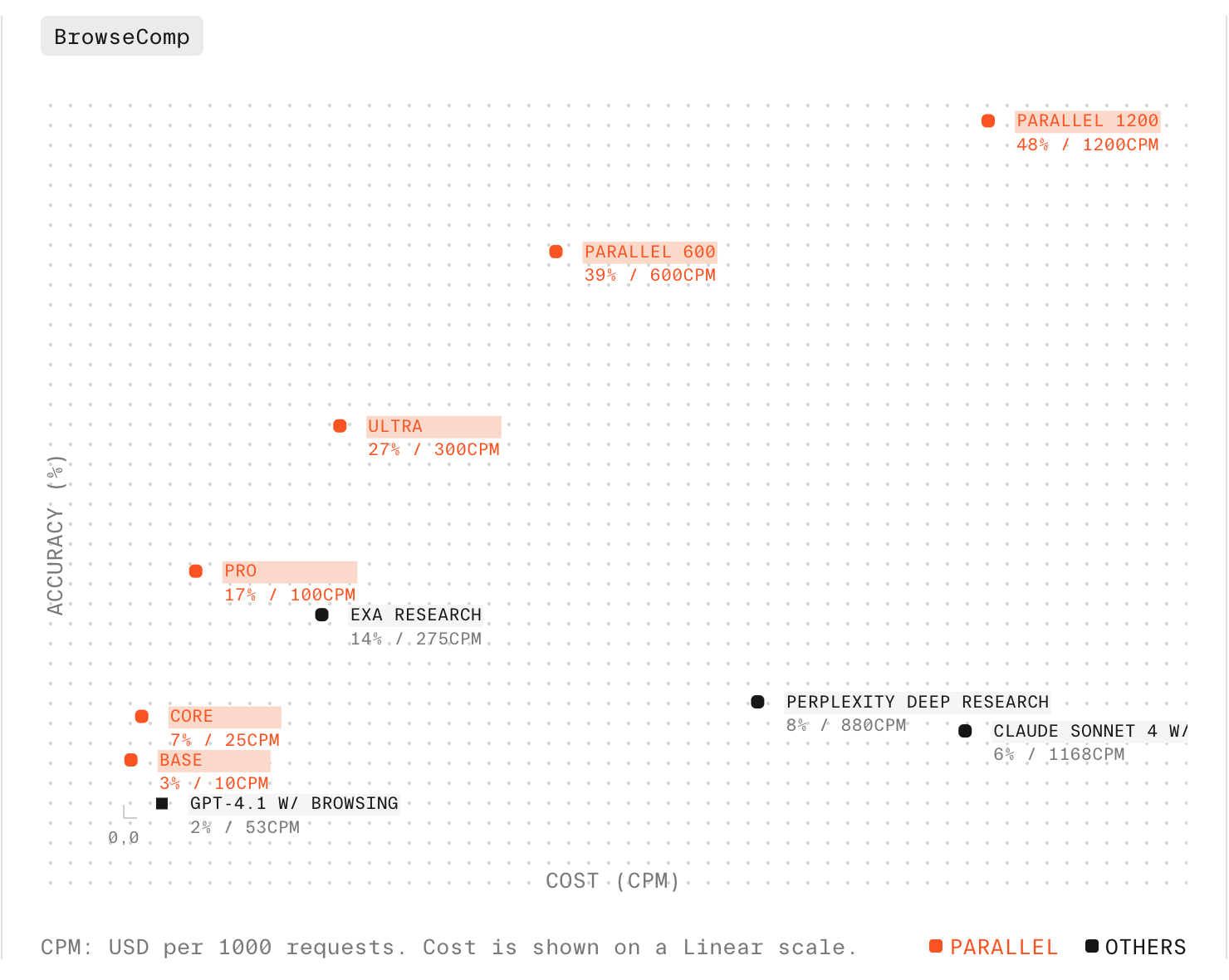
Search API in beta
The Parallel Search API is now available in beta - providing a tool for AI agents to search, rank, and extract information from the public web. Built on Parallel’s custom web crawler and index, the Search API takes flexible inputs (search objective and/or search queries) and returns LLM-ready ranked URLs with extended webpage excerpts. Learn more in our latest blog.Bugs (1)
Bugs (1)
- [Platform] Fixed an issue where copy paste URL actions were incorrectly identified as copy paste CSV actions.
Chat API in beta
Parallel Chat is now generally available in beta. The Chat API utilizes our rapidly growing web index to bring real-time low latency web research to interactive AI applications. It returns OpenAI ChatCompletions compatible streaming text and JSON outputs, and easily drops in to new and existing web research workflows. Learn more in our latest blog.Bugs (1)
Bugs (1)
- [Task API] Fixed an issue where the Task API was returning malformed schema formats.
Basis with Calibrated Confidences
Basis is a comprehensive suite of verification tools for understanding and validating Task API outputs through four core components.- Citations: Web URLs linking directly to source materials.
- Reasoning: Detailed explanations justifying each output field.
- Excerpts: Relevant text snippets from citation URLs.
- Confidences: A calibrated measure of confidence classified into low, medium, or high categories.
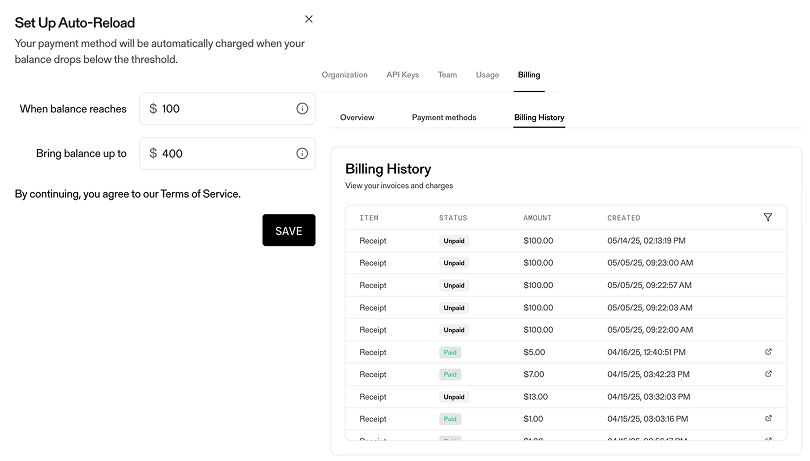
Billing Upgrades
We’ve made several improvements to help you more seamlessly manage and monitor Billing. This includes:- Auto-reload: Avoid service interruptions by automatically adding to your balance when configured thresholds are met.
- Billing History: View prior Invoices and Receipts. Track status, amount charged, and timestamp of charges.
Bugs (1)
Bugs (1)
- [Task API] Top-level output fields now correctly return null when appropriate, rather than lower-level fields returning empty string.
Improvements (2)
Improvements (2)
- [Task API] Improved
proandultraresponses for length list-style responses. - [Platform] The improved Parallel playground is now available by default at platform.parallel.ai/play instead of platform.parallel.ai/playground.
Task API for web research
Parallel Tasks enables state-of-the-art web research at scale, with the highest quality at every price point. State your research task in natural language and Parallel will do the rest of the heavy lifting - generating input/output schemas, finding relevant URLs, extracting data in a structured format.Python SDK
Our SDK is now available for Python, making it easy to implement Parallel into your applications. The Python SDK is at parity with our Task API endpoints and simplifies request construction and response parsing.Flexible Processors
When running Tasks with Parallel, choose between 5 processors -lite, base, core, pro, and ultra. We’ve built distinct processor options so that you can optimize price, latency, and quality per task.Self-Serve Developer Platform
Platform is the home for Playground, API Keys, Docs, Billing, Usage, and more.- Run a research task from scratch or using a template from Task Library
- Generate and manage API keys for secure integration
- Manage billing details, auto-reload settings, and usage analytics
- Access comprehensive guides to learn how to use the API
